Note
This is an auto-generated static view of a Jupyter notebook.
To run the code examples in your computer, you may download the original notebook from the repository: https://github.com/gsi-upm/senpy/tree/master/docs/Advanced.ipynb
Advanced features¶
This tutorial takes up where the basic tutorial left off.
It covers more advanced tasks such as:
Listing available services in an endpoint
Transforming the results of a service
Calling multiple services in the same request (Pipelines)
Running your own Senpy instance
Requirements¶
Once again we will use the demo server at http://senpy.gsi.upm.es, and a function to prettify the semantic output.
[1]:
endpoint = 'http://senpy.gsi.upm.es/api'
[2]:
import requests
from IPython.display import Code
def query(endpoint, raw=False, **kwargs):
'''Query a given Senpy endpoint with specific parameters, and prettify the output'''
res = requests.get(endpoint,
params=kwargs)
if raw:
return res
return Code(res.text, language=kwargs.get('outformat', 'json-ld'))
Selecting fields from the output¶
The full output in the previous tutorials is very useful because it is semantically annotated. However, it is also quite verbose if we only want to label a piece of text, or get a polarity value.
For such simple cases, the API has a special fields method you can use to get a specific field from the results, and even transform the results. Senpy uses jmespath under the hood, which has its own notation.
To illustrate this, let us get only the text (nif:isString) from each entry:
[3]:
query(f'{endpoint}/sentiment140',
input="Senpy is a wonderful service",
fields='entries[]."nif:isString"')
[3]:
["Senpy is a wonderful service"]
Or we could get both the text and the polarity of the text (assuming there is only one opinion per entry) with a slightly more complicated query:
[4]:
query(f'{endpoint}/sentiment140',
input="Senpy is a service. Wonderful service.",
delimiter="sentence",
fields='entries[0].["nif:isString", "marl:hasOpinion"[0]."marl:hasPolarity"]')
[4]:
["Senpy is a service. Wonderful service.", "marl:Neutral"]
jmespath is rather extensive for this tutorial. We will cover only the most simple cases, so you do not need to learn much about the notation.
For more complicated transformations, check out jmespath. In addition to a fairly complete documentation, they have a live environment you can use to test your queries.
Emotion conversion with field selection¶
We could mix emotion conversion with field selection to only get the label of an emotion analysis that has been automatically converted:
[5]:
query(f'{endpoint}/emotion-anew',
input="Senpy is a wonderful service and I love it",
emotionmodel="emoml:big6",
fields='entries[].[["nif:isString","onyx:hasEmotionSet"[]."onyx:hasEmotion"[]."onyx:hasEmotionCategory"][]][]',
conversion="filtered")
[5]:
[["Senpy is a wonderful service and I love it"]]
Building pipelines¶
You can query several senpy services in the same request. This feature is called pipelining, and the result of combining several plugins in a request is called a pipeline.
The simplest way to use pipelines is to add every plugin you want to use to the URL, separated by either a slash or a comma.
For instance, to get sentiment (sentiment140) and emotion (depechemood) annotations at the same time:
[6]:
query(f'{endpoint}/sentiment140/emotion-depechemood',
input="Senpy is a wonderful service")
[6]:
{
"@context": "http://senpy.gsi.upm.es/api/contexts/YXBpL3NlbnRpbWVudDE0MC9lbW90aW9uLWRlcGVjaGVtb29kP2lucHV0PVNlbnB5K2lzK2Erd29uZGVyZnVsK3NlcnZpY2Uj",
"@type": "Results",
"entries": [
{
"@id": "prefix:",
"@type": "Entry",
"marl:hasOpinion": [
{
"@type": "Sentiment",
"marl:hasPolarity": "marl:Neutral",
"prov:wasGeneratedBy": "prefix:Analysis_1563369539.5176148"
}
],
"nif:isString": "Senpy is a wonderful service",
"onyx:hasEmotionSet": [
{
"@type": "EmotionSet",
"onyx:hasEmotion": [
{
"@type": "Emotion",
"onyx:hasEmotionCategory": "wna:negative-fear",
"onyx:hasEmotionIntensity": 0.06258366271018097
},
{
"@type": "Emotion",
"onyx:hasEmotionCategory": "wna:amusement",
"onyx:hasEmotionIntensity": 0.15784834034155437
},
{
"@type": "Emotion",
"onyx:hasEmotionCategory": "wna:anger",
"onyx:hasEmotionIntensity": 0.08728815135373413
},
{
"@type": "Emotion",
"onyx:hasEmotionCategory": "wna:annoyance",
"onyx:hasEmotionIntensity": 0.12184635680460143
},
{
"@type": "Emotion",
"onyx:hasEmotionCategory": "wna:indifference",
"onyx:hasEmotionIntensity": 0.1374081151031531
},
{
"@type": "Emotion",
"onyx:hasEmotionCategory": "wna:joy",
"onyx:hasEmotionIntensity": 0.12267040802346799
},
{
"@type": "Emotion",
"onyx:hasEmotionCategory": "wna:awe",
"onyx:hasEmotionIntensity": 0.21085262130713067
},
{
"@type": "Emotion",
"onyx:hasEmotionCategory": "wna:sadness",
"onyx:hasEmotionIntensity": 0.09950234435617733
}
],
"prov:wasGeneratedBy": "prefix:Analysis_1563369539.5185866"
}
]
}
]
}
In a senpy pipeline, the call is processed by each plugin in sequence. The output of a plugin is used as input for the next one.
Pipelines take the same parameters as the plugins they are made of. For example, if we want to split the original sentence before analysing its sentiment, we can use a pipeline made out of the split and the sentiment140 plugins.
split takes an extra parameter (delimiter) to select the type of splitting (by sentence or by paragraph), and sentiment140 takes a language parameter.
This is how the request looks like:
[7]:
query(f'{endpoint}/split/sentiment140',
input="Senpy is awesome. And services are composable.",
delimiter="sentence",
language="en",
outformat="json-ld")
[7]:
{
"@context": "http://senpy.gsi.upm.es/api/contexts/YXBpL3NwbGl0L3NlbnRpbWVudDE0MD9pbnB1dD1TZW5weStpcythd2Vzb21lLitBbmQrc2VydmljZXMrYXJlK2NvbXBvc2FibGUuJmRlbGltaXRlcj1zZW50ZW5jZSZsYW5ndWFnZT1lbiZvdXRmb3JtYXQ9anNvbi1sZCM%3D",
"@type": "Results",
"entries": [
{
"@id": "prefix:",
"@type": "Entry",
"marl:hasOpinion": [
{
"@type": "Sentiment",
"marl:hasPolarity": "marl:Positive",
"prov:wasGeneratedBy": "prefix:Analysis_1563369539.7878842"
}
],
"nif:isString": "Senpy is awesome. And services are composable.",
"onyx:hasEmotionSet": []
},
{
"@id": "prefix:#char=0,17",
"@type": "Entry",
"marl:hasOpinion": [
{
"@type": "Sentiment",
"marl:hasPolarity": "marl:Positive",
"prov:wasGeneratedBy": "prefix:Analysis_1563369539.7878842"
}
],
"nif:isString": "Senpy is awesome.",
"onyx:hasEmotionSet": []
},
{
"@id": "prefix:#char=18,46",
"@type": "Entry",
"marl:hasOpinion": [
{
"@type": "Sentiment",
"marl:hasPolarity": "marl:Neutral",
"prov:wasGeneratedBy": "prefix:Analysis_1563369539.7878842"
}
],
"nif:isString": "And services are composable.",
"onyx:hasEmotionSet": []
}
]
}
As you can see, split creates two new entries, which are also annotated by sentiment140.
Once again, we could use the fields parameter to get a list of strings and labels:
[8]:
query(f'{endpoint}/split/sentiment140',
input="Senpy is awesome. And services are composable.",
delimiter="sentence",
fields='entries[].[["nif:isString","marl:hasOpinion"[]."marl:hasPolarity"][]][]',
language="en",
outformat="json-ld")
[8]:
[["Senpy is awesome. And services are composable.", "marl:Positive"], ["Senpy is awesome.", "marl:Positive"], ["And services are composable.", "marl:Neutral"]]
Listing services¶
You can get a complete list of plugins in a senpy instance through the API:
[9]:
query(f'{endpoint}/plugins')
[9]:
{
"@context": "http://senpy.gsi.upm.es/api/contexts/YXBpL3BsdWdpbnMvPyM%3D",
"@type": "Plugins",
"plugins": [
{
"@id": "endpoint:plugins/emotion-anew_0.5.1",
"@type": "EmotionPlugin",
"author": "@icorcuera",
"description": "This plugin consists on an emotion classifier using ANEW lexicon dictionary to calculate VAD (valence-arousal-dominance) of the sentence and determinate which emotion is closer to this value. Each emotion has a centroid, calculated according to this article: http://www.aclweb.org/anthology/W10-0208. The plugin is going to look for the words in the sentence that appear in the ANEW dictionary and calculate the average VAD score for the sentence. Once this score is calculated, it is going to seek the emotion that is closest to this value.",
"extra_params": {
"language": {
"aliases": [
"language",
"l"
],
"default": "en",
"description": "language of the input",
"options": [
"es",
"en"
],
"required": true
}
},
"is_activated": true,
"maxEmotionValue": 1,
"minEmotionValue": 0,
"name": "emotion-anew",
"version": "0.5.1"
},
{
"@id": "endpoint:plugins/emotion-depechemood_0.1",
"@type": "EmotionPlugin",
"author": "Oscar Araque",
"description": "\nPlugin that uses the DepecheMood emotion lexicon.\n\nDepecheMood is an emotion lexicon automatically generated from news articles where users expressed their associated emotions. It contains two languages (English and Italian), as well as three types of word representations (token, lemma and lemma#PoS). For English, the lexicon contains 165k tokens, while the Italian version contains 116k. Unsupervised techniques can be applied to generate simple but effective baselines. To learn more, please visit https://github.com/marcoguerini/DepecheMood and http://www.depechemood.eu/\n",
"extra_params": {},
"is_activated": true,
"maxEmotionValue": 1,
"minEmotionValue": 0,
"name": "emotion-depechemood",
"version": "0.1"
},
{
"@id": "endpoint:plugins/emotion-wnaffect_0.2",
"@type": "EmotionPlugin",
"author": [
"@icorcuera",
"@balkian"
],
"description": "\nEmotion classifier using WordNet-Affect to calculate the percentage\nof each emotion. This plugin classifies among 6 emotions: anger,fear,disgust,joy,sadness\nor neutral. The only available language is English (en)\n",
"extra_params": {
"language": {
"@id": "lang_wnaffect",
"aliases": [
"language",
"l"
],
"description": "language of the input",
"options": [
"en"
],
"required": true
}
},
"is_activated": true,
"maxEmotionValue": 1,
"minEmotionValue": 0,
"name": "emotion-wnaffect",
"version": "0.2"
},
{
"@id": "endpoint:plugins/example-plugin_0.1",
"@type": "Plugin",
"author": "@balkian",
"description": "A *VERY* simple plugin that exemplifies the development of Senpy Plugins",
"extra_params": {
"parameter": {
"@id": "parameter",
"aliases": [
"parameter",
"param"
],
"default": 42,
"description": "this parameter does nothing, it is only an example",
"required": true
}
},
"is_activated": true,
"name": "example-plugin",
"version": "0.1"
},
{
"@id": "endpoint:plugins/sentiment-basic_0.1.1",
"@type": "SentimentPlugin",
"author": "github.com/nachtkatze",
"description": "\nSentiment classifier using rule-based classification for Spanish. Based on english to spanish translation and SentiWordNet sentiment knowledge. This is a demo plugin that uses only some features from the TASS 2015 classifier. To use the entirely functional classifier you can use the service in: http://senpy.gsi.upm.es.\n",
"extra_params": {
"language": {
"aliases": [
"language",
"l"
],
"default": "en",
"description": "language of the text",
"options": [
"en",
"es",
"it",
"fr"
],
"required": true
}
},
"is_activated": true,
"maxPolarityValue": 1,
"minPolarityValue": -1,
"name": "sentiment-basic",
"version": "0.1.1"
},
{
"@id": "endpoint:plugins/sentiment-meaningcloud_1.1",
"@type": "SentimentPlugin",
"author": "GSI UPM",
"description": "\nSentiment analysis with meaningCloud service.\nTo use this plugin, you need to obtain an API key from meaningCloud signing up here:\nhttps://www.meaningcloud.com/developer/login\n\nWhen you had obtained the meaningCloud API Key, you have to provide it to the plugin, using param apiKey.\nExample request:\n\nhttp://senpy.gsi.upm.es/api/?algo=meaningCloud&language=en&apiKey=YOUR_API_KEY&input=I%20love%20Madrid.\n",
"extra_params": {
"apikey": {
"aliases": [
"apiKey",
"meaningcloud-key",
"meaningcloud-apikey"
],
"description": "API key for the meaningcloud service. See https://www.meaningcloud.com/developer/login",
"required": true
},
"language": {
"aliases": [
"language",
"l"
],
"default": "auto",
"description": "language of the input",
"options": [
"en",
"es",
"ca",
"it",
"pt",
"fr",
"auto"
],
"required": true
}
},
"is_activated": true,
"maxPolarityValue": 1,
"minPolarityValue": -1,
"name": "sentiment-meaningcloud",
"version": "1.1"
},
{
"@id": "endpoint:plugins/sentiment-vader_0.1.1",
"@type": "SentimentPlugin",
"author": "@icorcuera",
"description": "\nSentiment classifier using vaderSentiment module. Params accepted: Language: {en, es}. The output uses Marl ontology developed at GSI UPM for semantic web.\n",
"extra_params": {
"aggregate": {
"aliases": [
"aggregate",
"agg"
],
"default": false,
"description": "Show only the strongest sentiment (aggregate) or all sentiments",
"options": [
true,
false
]
},
"language": {
"@id": "lang_rand",
"aliases": [
"language",
"l"
],
"default": "auto",
"description": "language of the input",
"options": [
"es",
"en",
"auto"
]
}
},
"is_activated": true,
"maxPolarityValue": 1,
"minPolarityValue": 0,
"name": "sentiment-vader",
"version": "0.1.1"
},
{
"@id": "endpoint:plugins/sentiment140_0.2",
"@type": "SentimentPlugin",
"author": "@balkian",
"description": "Connects to the sentiment140 free API: http://sentiment140.com",
"extra_params": {
"language": {
"@id": "lang_sentiment140",
"aliases": [
"language",
"l"
],
"default": "auto",
"description": "language of the text",
"options": [
"es",
"en",
"auto"
],
"required": true
}
},
"is_activated": true,
"maxPolarityValue": 1,
"minPolarityValue": 0,
"name": "sentiment140",
"url": "https://github.com/gsi-upm/senpy-plugins-community",
"version": "0.2"
},
{
"@id": "endpoint:plugins/split_0.3",
"@type": "Plugin",
"author": [
"@militarpancho",
"@balkian"
],
"description": "\nA plugin that chunks input text, into paragraphs or sentences.\n\nIt does not provide any sort of annotation, and it is meant to precede\nother annotation plugins, when the annotation of individual sentences\n(or paragraphs) is required.\n",
"extra_params": {
"delimiter": {
"aliases": [
"type",
"t"
],
"default": "sentence",
"description": "Split text into paragraphs or sentences.",
"options": [
"sentence",
"paragraph"
],
"required": false
}
},
"is_activated": true,
"name": "split",
"url": "https://github.com/gsi-upm/senpy",
"version": "0.3"
}
]
}
If you want to get only a specific type of plugin, use the plugin_type parameter. e.g., this will only return the plugins for sentiment analysis:
[10]:
query(f'{endpoint}/plugins',
plugin_type="SentimentPlugin")
[10]:
{
"@context": "http://senpy.gsi.upm.es/api/contexts/YXBpL3BsdWdpbnMvP3BsdWdpbl90eXBlPVNlbnRpbWVudFBsdWdpbiM%3D",
"@type": "Plugins",
"plugins": [
{
"@id": "endpoint:plugins/sentiment-basic_0.1.1",
"@type": "SentimentPlugin",
"author": "github.com/nachtkatze",
"description": "\nSentiment classifier using rule-based classification for Spanish. Based on english to spanish translation and SentiWordNet sentiment knowledge. This is a demo plugin that uses only some features from the TASS 2015 classifier. To use the entirely functional classifier you can use the service in: http://senpy.gsi.upm.es.\n",
"extra_params": {
"language": {
"aliases": [
"language",
"l"
],
"default": "en",
"description": "language of the text",
"options": [
"en",
"es",
"it",
"fr"
],
"required": true
}
},
"is_activated": true,
"maxPolarityValue": 1,
"minPolarityValue": -1,
"name": "sentiment-basic",
"version": "0.1.1"
},
{
"@id": "endpoint:plugins/sentiment-meaningcloud_1.1",
"@type": "SentimentPlugin",
"author": "GSI UPM",
"description": "\nSentiment analysis with meaningCloud service.\nTo use this plugin, you need to obtain an API key from meaningCloud signing up here:\nhttps://www.meaningcloud.com/developer/login\n\nWhen you had obtained the meaningCloud API Key, you have to provide it to the plugin, using param apiKey.\nExample request:\n\nhttp://senpy.gsi.upm.es/api/?algo=meaningCloud&language=en&apiKey=YOUR_API_KEY&input=I%20love%20Madrid.\n",
"extra_params": {
"apikey": {
"aliases": [
"apiKey",
"meaningcloud-key",
"meaningcloud-apikey"
],
"description": "API key for the meaningcloud service. See https://www.meaningcloud.com/developer/login",
"required": true
},
"language": {
"aliases": [
"language",
"l"
],
"default": "auto",
"description": "language of the input",
"options": [
"en",
"es",
"ca",
"it",
"pt",
"fr",
"auto"
],
"required": true
}
},
"is_activated": true,
"maxPolarityValue": 1,
"minPolarityValue": -1,
"name": "sentiment-meaningcloud",
"version": "1.1"
},
{
"@id": "endpoint:plugins/sentiment-vader_0.1.1",
"@type": "SentimentPlugin",
"author": "@icorcuera",
"description": "\nSentiment classifier using vaderSentiment module. Params accepted: Language: {en, es}. The output uses Marl ontology developed at GSI UPM for semantic web.\n",
"extra_params": {
"aggregate": {
"aliases": [
"aggregate",
"agg"
],
"default": false,
"description": "Show only the strongest sentiment (aggregate) or all sentiments",
"options": [
true,
false
]
},
"language": {
"@id": "lang_rand",
"aliases": [
"language",
"l"
],
"default": "auto",
"description": "language of the input",
"options": [
"es",
"en",
"auto"
]
}
},
"is_activated": true,
"maxPolarityValue": 1,
"minPolarityValue": 0,
"name": "sentiment-vader",
"version": "0.1.1"
},
{
"@id": "endpoint:plugins/sentiment140_0.2",
"@type": "SentimentPlugin",
"author": "@balkian",
"description": "Connects to the sentiment140 free API: http://sentiment140.com",
"extra_params": {
"language": {
"@id": "lang_sentiment140",
"aliases": [
"language",
"l"
],
"default": "auto",
"description": "language of the text",
"options": [
"es",
"en",
"auto"
],
"required": true
}
},
"is_activated": true,
"maxPolarityValue": 1,
"minPolarityValue": 0,
"name": "sentiment140",
"url": "https://github.com/gsi-upm/senpy-plugins-community",
"version": "0.2"
}
]
}
The fields parameter also works on the plugins API:
[11]:
query(f'{endpoint}/plugins',
fields='plugins[].["@id","@type"]')
[11]:
[["endpoint:plugins/emotion-anew_0.5.1", "EmotionPlugin"], ["endpoint:plugins/emotion-depechemood_0.1", "EmotionPlugin"], ["endpoint:plugins/emotion-wnaffect_0.2", "EmotionPlugin"], ["endpoint:plugins/example-plugin_0.1", "Plugin"], ["endpoint:plugins/sentiment-basic_0.1.1", "SentimentPlugin"], ["endpoint:plugins/sentiment-meaningcloud_1.1", "SentimentPlugin"], ["endpoint:plugins/sentiment-vader_0.1.1", "SentimentPlugin"], ["endpoint:plugins/sentiment140_0.2", "SentimentPlugin"], ["endpoint:plugins/split_0.3", "Plugin"]]
Alternatively:
Evaluation¶
Sentiment analysis plugins can also be evaluated on a series of pre-defined datasets, using the gsitk tool.
For instance, to evaluate the sentiment-vader plugin on the vader and sts datasets, we would simply call:
[12]:
query(f'{endpoint}/evaluate',
algo="sentiment-vader",
dataset="vader,sts",
outformat='json-ld')
[12]:
{
"@context": "http://senpy.gsi.upm.es/api/contexts/YXBpL2V2YWx1YXRlLz9hbGdvPXNlbnRpbWVudC12YWRlciZkYXRhc2V0PXZhZGVyJTJDc3RzJm91dGZvcm1hdD1qc29uLWxkIw%3D%3D",
"@type": "AggregatedEvaluation",
"senpy:evaluations": [
{
"@type": "Evaluation",
"evaluates": "endpoint:plugins/sentiment-vader_0.1.1__vader",
"evaluatesOn": "vader",
"metrics": [
{
"@type": "Accuracy",
"value": 0.6907142857142857
},
{
"@type": "Precision_macro",
"value": 0.34535714285714286
},
{
"@type": "Recall_macro",
"value": 0.5
},
{
"@type": "F1_macro",
"value": 0.40853400929446554
},
{
"@type": "F1_weighted",
"value": 0.5643605528396403
},
{
"@type": "F1_micro",
"value": 0.6907142857142857
},
{
"@type": "F1_macro",
"value": 0.40853400929446554
}
]
},
{
"@type": "Evaluation",
"evaluates": "endpoint:plugins/sentiment-vader_0.1.1__sts",
"evaluatesOn": "sts",
"metrics": [
{
"@type": "Accuracy",
"value": 0.3107177974434612
},
{
"@type": "Precision_macro",
"value": 0.1553588987217306
},
{
"@type": "Recall_macro",
"value": 0.5
},
{
"@type": "F1_macro",
"value": 0.23705926481620407
},
{
"@type": "F1_weighted",
"value": 0.14731706525451424
},
{
"@type": "F1_micro",
"value": 0.3107177974434612
},
{
"@type": "F1_macro",
"value": 0.23705926481620407
}
]
}
]
}
The same results can be visualized as a table in the Web interface:
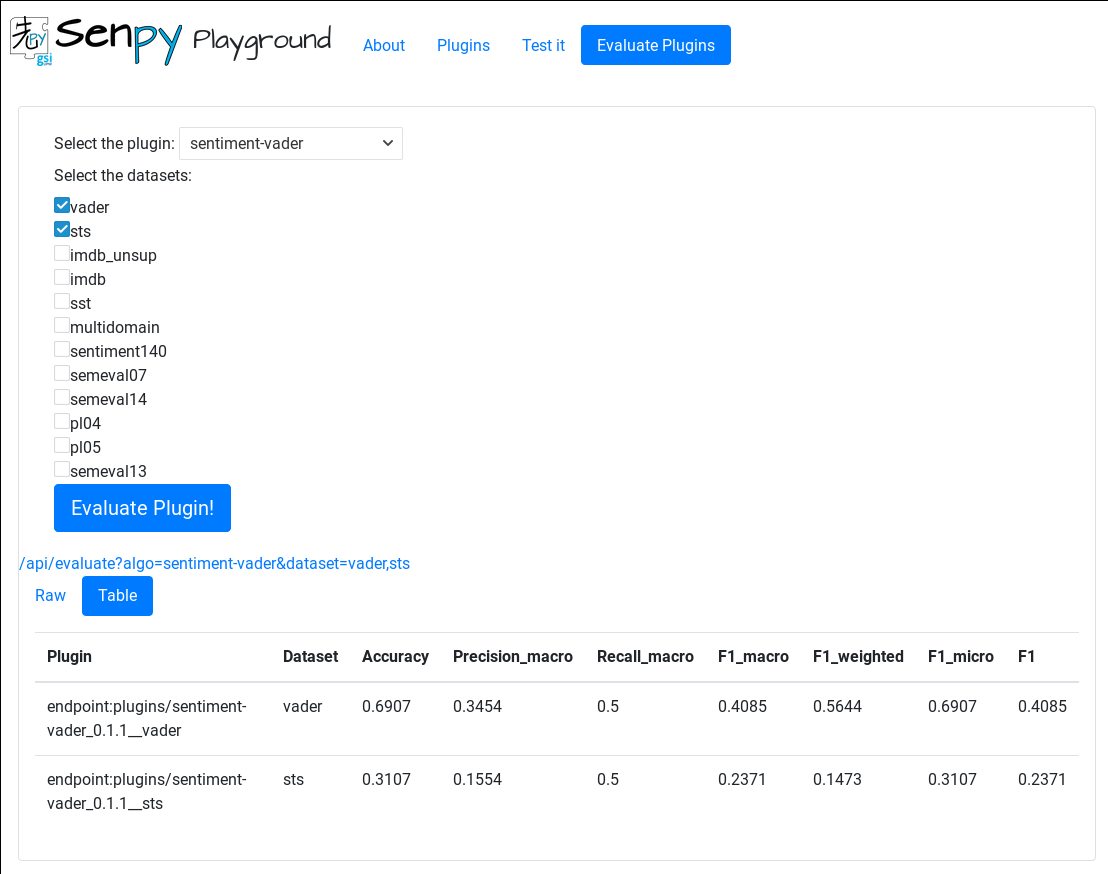
note: to evaluate a plugin on a dataset, senpy will need to predict the labels of the entries using the plugin. This process might take long for plugins that use an external service, such as sentiment140.
Running your own senpy instance with Docker¶
Now that you’re familiar with Senpy, you can deploy your own instance quite easily. e.g. using docker:
docker run -ti --name 'SenpyEndpoint' -d -p 5000:5000 gsiupm/senpy
Alternatively, you can install senpy in your system and run it:
# First install it
pip install --user senpy
# Run locally
senpy
# or
python -m senpy
Once you have an instance running, feel free to change the endpoint variable to run the examples in your own instance.
Advanced topics¶
Verbose output¶
By default, senpy does not include information that might be too verbose, such as the parameters that were used in the analysis.
You can instruct senpy to provide a more verbose output with the verbose parameter:
[13]:
query(f'{endpoint}/sentiment140',
input="Senpy is the best framework for semantic sentiment analysis, and very easy to use",
verbose=True)
[13]:
{
"@context": "http://senpy.gsi.upm.es/api/contexts/YXBpL3NlbnRpbWVudDE0MD9pbnB1dD1TZW5weStpcyt0aGUrYmVzdCtmcmFtZXdvcmsrZm9yK3NlbWFudGljK3NlbnRpbWVudCthbmFseXNpcyUyQythbmQrdmVyeStlYXN5K3RvK3VzZSZ2ZXJib3NlPVRydWUj",
"@type": "Results",
"activities": [
{
"@id": "prefix:Analysis_1563369541.408701",
"@type": "Analysis",
"marl:maxPolarityValue": 1,
"marl:minPolarityValue": 0,
"prov:used": [
{
"@type": "Parameter",
"name": "input",
"value": "Senpy is the best framework for semantic sentiment analysis, and very easy to use"
},
{
"@type": "Parameter",
"name": "verbose",
"value": true
},
{
"@type": "Parameter",
"name": "in-headers",
"value": false
},
{
"@type": "Parameter",
"name": "algorithm",
"value": "default"
},
{
"@type": "Parameter",
"name": "expanded-jsonld",
"value": false
},
{
"@type": "Parameter",
"name": "with-parameters",
"value": false
},
{
"@type": "Parameter",
"name": "outformat",
"value": "json-ld"
},
{
"@type": "Parameter",
"name": "help",
"value": false
},
{
"@type": "Parameter",
"name": "aliases",
"value": false
},
{
"@type": "Parameter",
"name": "conversion",
"value": "full"
},
{
"@type": "Parameter",
"name": "intype",
"value": "direct"
},
{
"@type": "Parameter",
"name": "informat",
"value": "text"
},
{
"@type": "Parameter",
"name": "prefix",
"value": ""
},
{
"@type": "Parameter",
"name": "urischeme",
"value": "RFC5147String"
},
{
"@type": "Parameter",
"name": "language",
"value": "auto"
}
],
"prov:wasAssociatedWith": "endpoint:plugins/sentiment140_0.2"
}
],
"entries": [
{
"@id": "prefix:",
"@type": "Entry",
"marl:hasOpinion": [
{
"@type": "Sentiment",
"marl:hasPolarity": "marl:Positive",
"prov:wasGeneratedBy": "prefix:Analysis_1563369541.408701"
}
],
"nif:isString": "Senpy is the best framework for semantic sentiment analysis, and very easy to use",
"onyx:hasEmotionSet": []
}
]
}
Getting help¶
[14]:
query(f'{endpoint}/',
help=True)
[14]:
{
"@context": "http://senpy.gsi.upm.es/api/contexts/YXBpLz9oZWxwPVRydWUj",
"@type": "Help",
"valid_parameters": {
"algorithm": {
"aliases": [
"algorithms",
"a",
"algo"
],
"default": "default",
"description": "Algorithms that will be used to process the request.It may be a list of comma-separated names.",
"processor": "string_to_tuple",
"required": true
},
"aliases": {
"@id": "aliases",
"aliases": [],
"default": false,
"description": "Replace JSON properties with their aliases",
"options": [
true,
false
],
"required": true
},
"conversion": {
"@id": "conversion",
"default": "full",
"description": "How to show the elements that have (not) been converted.\n\n* full: converted and original elements will appear side-by-side\n* filtered: only converted elements will be shown\n* nested: converted elements will be shown, and they will include a link to the original element\n(using `prov:wasGeneratedBy`).\n",
"options": [
"filtered",
"nested",
"full"
],
"required": true
},
"emotion-model": {
"@id": "emotionModel",
"aliases": [
"emoModel",
"emotionModel"
],
"description": "Emotion model to use in the response.\nSenpy will try to convert the output to this model automatically.\n\nExamples: `wna:liking` and `emoml:big6`.\n ",
"required": false
},
"expanded-jsonld": {
"@id": "expanded-jsonld",
"aliases": [
"expanded",
"expanded_jsonld"
],
"default": false,
"description": "use JSON-LD expansion to get full URIs",
"options": [
true,
false
],
"required": true
},
"fields": {
"@id": "fields",
"description": "A jmespath selector, that can be used to extract a new dictionary, array or value\nfrom the results.\njmespath is a powerful query language for json and/or dictionaries.\nIt allows you to change the structure (and data) of your objects through queries.\n\ne.g., the following expression gets a list of `[emotion label, intensity]` for each entry:\n`entries[].\"onyx:hasEmotionSet\"[].\"onyx:hasEmotion\"[][\"onyx:hasEmotionCategory\",\"onyx:hasEmotionIntensity\"]`\n\nFor more information, see: https://jmespath.org\n\n",
"required": false
},
"help": {
"@id": "help",
"aliases": [
"h"
],
"default": false,
"description": "Show additional help to know more about the possible parameters",
"options": [
true,
false
],
"required": true
},
"in-headers": {
"aliases": [
"headers",
"inheaders",
"inHeaders",
"in-headers",
"in_headers"
],
"default": false,
"description": "Only include the JSON-LD context in the headers",
"options": [
true,
false
],
"required": true
},
"informat": {
"@id": "informat",
"aliases": [
"f"
],
"default": "text",
"description": "input format",
"options": [
"text",
"json-ld"
],
"required": false
},
"input": {
"@id": "input",
"aliases": [
"i"
],
"help": "Input text",
"required": true
},
"intype": {
"@id": "intype",
"aliases": [
"t"
],
"default": "direct",
"description": "input type",
"options": [
"direct",
"url",
"file"
],
"required": false
},
"language": {
"aliases": [
"language",
"l"
],
"default": "en",
"description": "language of the input",
"options": [
"es",
"en"
],
"required": true
},
"outformat": {
"@id": "outformat",
"aliases": [
"o"
],
"default": "json-ld",
"description": "The data can be semantically formatted (JSON-LD, turtle or n-triples),\ngiven as a list of comma-separated fields (see the fields option) or constructed from a Jinja2\ntemplate (see the template option).",
"options": [
"json-ld",
"turtle",
"ntriples"
],
"required": true
},
"prefix": {
"@id": "prefix",
"aliases": [
"p"
],
"default": "",
"description": "prefix to use for new entities",
"required": true
},
"template": {
"@id": "template",
"description": "Jinja2 template for the result. The input data for the template will\nbe the results as a dictionary.\nFor example:\n\nConsider the results before templating:\n\n```\n[{\n \"@type\": \"entry\",\n \"onyx:hasEmotionSet\": [],\n \"nif:isString\": \"testing the template\",\n \"marl:hasOpinion\": [\n {\n \"@type\": \"sentiment\",\n \"marl:hasPolarity\": \"marl:Positive\"\n }\n ]\n}]\n```\n\n\nAnd the template:\n\n```\n{% for entry in entries %}\n{{ entry[\"nif:isString\"] | upper }},{{entry.sentiments[0][\"marl:hasPolarity\"].split(\":\")[1]}}\n{% endfor %}\n```\n\nThe final result would be:\n\n```\nTESTING THE TEMPLATE,Positive\n```\n",
"required": false
},
"urischeme": {
"@id": "urischeme",
"aliases": [
"u"
],
"default": "RFC5147String",
"description": "scheme for NIF URIs",
"options": [
"RFC5147String"
],
"required": false
},
"verbose": {
"@id": "verbose",
"aliases": [
"v"
],
"default": false,
"description": "Show all properties in the result",
"options": [
true,
false
],
"required": true
},
"with-parameters": {
"aliases": [
"withparameters",
"with_parameters"
],
"default": false,
"description": "include initial parameters in the response",
"options": [
true,
false
],
"required": true
}
}
}
Ignoring the context¶
[15]:
query(f'{endpoint}/',
input="This will tell senpy to only include the context in the headers",
inheaders=True)
[15]:
{
"@type": "Results",
"entries": [
{
"@id": "prefix:",
"@type": "Entry",
"marl:hasOpinion": [],
"nif:isString": "This will tell senpy to only include the context in the headers",
"onyx:hasEmotionSet": [
{
"@id": "Emotions0",
"@type": "EmotionSet",
"onyx:hasEmotion": [
{
"@id": "Emotion0",
"@type": "Emotion",
"http://www.gsi.upm.es/ontologies/onyx/vocabularies/anew/ns#arousal": 4.22,
"http://www.gsi.upm.es/ontologies/onyx/vocabularies/anew/ns#dominance": 5.17,
"http://www.gsi.upm.es/ontologies/onyx/vocabularies/anew/ns#valence": 5.2,
"prov:wasGeneratedBy": "prefix:Analysis_1563369541.631805"
}
],
"prov:wasGeneratedBy": "prefix:Analysis_1563369541.631805"
}
]
}
]
}
To retrieve the context URI, use the LINK header:
[16]:
# We first repeat the query, to get the raw requests response using raw=True
res = query(f'{endpoint}/', input="This will tell senpy to only include the context in the headers", inheaders=True, raw=True)
# The URI of the context is in the headers:
print(res.headers['Link'])
<http://senpy.gsi.upm.es/api/contexts/YXBpLz9pbnB1dD1UaGlzK3dpbGwrdGVsbCtzZW5weSt0bytvbmx5K2luY2x1ZGUrdGhlK2NvbnRleHQraW4rdGhlK2hlYWRlcnMmaW5oZWFkZXJzPVRydWUj>;rel="http://www.w3.org/ns/json-ld#context"; type="application/ld+json"

