Note
This is an auto-generated static view of a Jupyter notebook.
To run the code examples in your computer, you may download the original notebook from the repository: https://github.com/gsi-upm/senpy/tree/master/docs/Evaluation.ipynb
Evaluating Services¶
Sentiment analysis plugins can also be evaluated on a series of pre-defined datasets. This can be done in three ways: through the Web UI (playground), through the web API and programmatically.
Regardless of the way you perform the evaluation, you will need to specify a plugin (service) that you want to evaluate, and a series of datasets on which it should be evaluated.
to evaluate a plugin on a dataset, senpy use the plugin to predict the sentiment in each entry in the dataset. These predictions are compared with the expected values to produce several metrics, such as: accuracy, precision and f1-score.
note: the evaluation process might take long for plugins that use external services, such as sentiment140.
note: plugins are assumed to be pre-trained and invariant. i.e., the prediction for an entry should
Web UI (Playground)¶
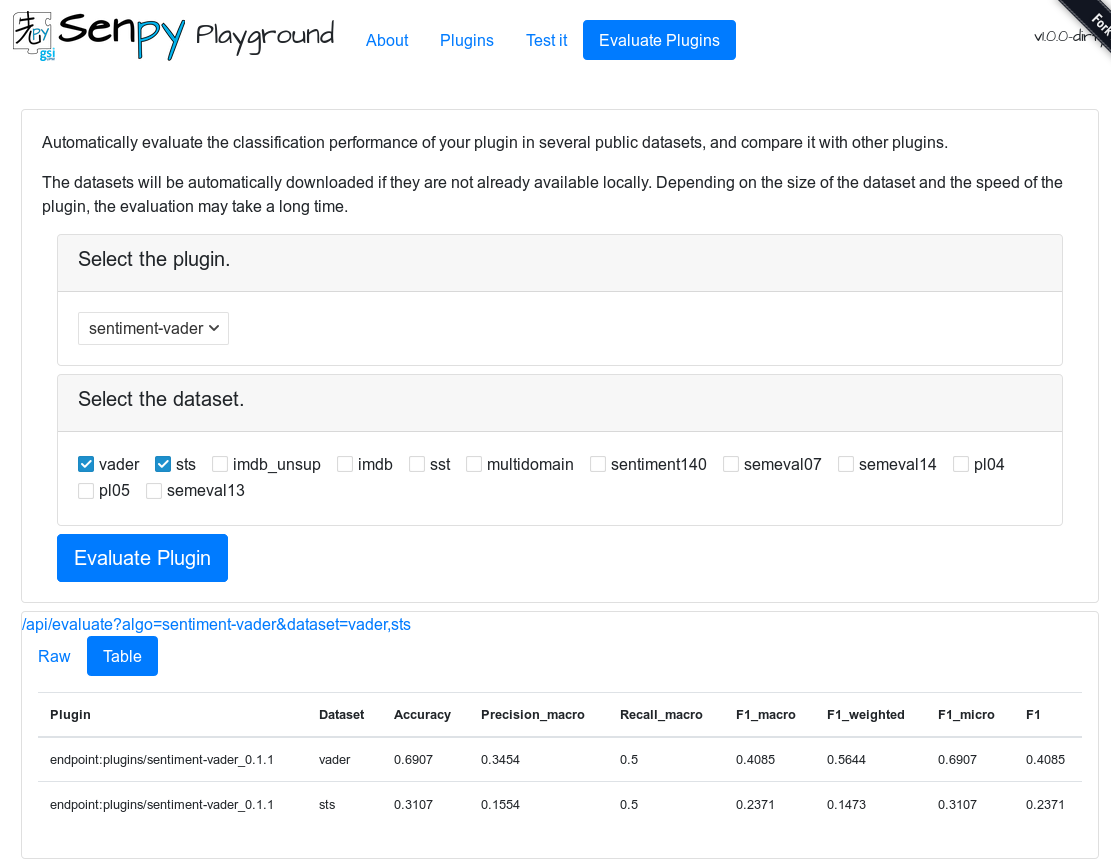
The playground should contain a tab for Evaluation, where you can select any plugin that can be evaluated, and the set of datasets that you want to test the plugin on.
For example, the image below shows the results of the sentiment-vader plugin on the vader and sts datasets:
Web API¶
The api exposes an endpoint (/evaluate), which accents the plugin and the set of datasets on which it should be evaluated.
The following code is not necessary, but it will display the results better:
Here is a simple call using the requests library:
[2]:
import requests
from IPython.display import Code
endpoint = 'http://senpy.gsi.upm.es/api'
res = requests.get(f'{endpoint}/evaluate',
params={"algo": "sentiment-vader",
"dataset": "vader,sts",
'outformat': 'json-ld'
})
Code(res.text, language='json')
[2]:
{
"@context": "http://senpy.gsi.upm.es/api/contexts/YXBpL2V2YWx1YXRlLz9hbGdvPXNlbnRpbWVudC12YWRlciZkYXRhc2V0PXZhZGVyJTJDc3RzJm91dGZvcm1hdD1qc29uLWxkIw%3D%3D",
"@type": "AggregatedEvaluation",
"senpy:evaluations": [
{
"@type": "Evaluation",
"evaluates": "endpoint:plugins/sentiment-vader_0.1.1__vader",
"evaluatesOn": "vader",
"metrics": [
{
"@type": "Accuracy",
"value": 0.6907142857142857
},
{
"@type": "Precision_macro",
"value": 0.34535714285714286
},
{
"@type": "Recall_macro",
"value": 0.5
},
{
"@type": "F1_macro",
"value": 0.40853400929446554
},
{
"@type": "F1_weighted",
"value": 0.5643605528396403
},
{
"@type": "F1_micro",
"value": 0.6907142857142857
},
{
"@type": "F1_macro",
"value": 0.40853400929446554
}
]
},
{
"@type": "Evaluation",
"evaluates": "endpoint:plugins/sentiment-vader_0.1.1__sts",
"evaluatesOn": "sts",
"metrics": [
{
"@type": "Accuracy",
"value": 0.3107177974434612
},
{
"@type": "Precision_macro",
"value": 0.1553588987217306
},
{
"@type": "Recall_macro",
"value": 0.5
},
{
"@type": "F1_macro",
"value": 0.23705926481620407
},
{
"@type": "F1_weighted",
"value": 0.14731706525451424
},
{
"@type": "F1_micro",
"value": 0.3107177974434612
},
{
"@type": "F1_macro",
"value": 0.23705926481620407
}
]
}
]
}
Programmatically (expert)¶
A third option is to evaluate plugins manually without launching the server.
This option is particularly interesting for advanced users that want faster iterations and evaluation results, and for automation.
We would first need an instance of a plugin. In this example we will use the Sentiment140 plugin that is included in every senpy installation:
[22]:
from senpy.plugins.sentiment import sentiment140_plugin
[23]:
s140 = sentiment140_plugin.Sentiment140()
Then, we need to know what datasets are available. We can list all datasets and basic stats (e.g., number of instances and labels used) like this:
[32]:
from senpy.gsitk_compat import datasets
for k, d in datasets.items():
print(k, d['stats'])
vader {'instances': 4200, 'labels': [1, -1]}
sts {'instances': 4200, 'labels': [1, -1]}
imdb_unsup {'instances': 50000, 'labels': [1, -1]}
imdb {'instances': 50000, 'labels': [1, -1]}
sst {'instances': 11855, 'labels': [1, -1]}
multidomain {'instances': 38548, 'labels': [1, -1]}
sentiment140 {'instances': 1600000, 'labels': [1, -1]}
semeval07 {'instances': 'None', 'labels': [1, -1]}
semeval14 {'instances': 7838, 'labels': [1, -1]}
pl04 {'instances': 4000, 'labels': [1, -1]}
pl05 {'instances': 10662, 'labels': [1, -1]}
semeval13 {'instances': 6259, 'labels': [1, -1]}
Now, we will evaluate our plugin in one of the smallest datasets, sts:
[37]:
s140.evaluate(['sts', ])
[37]:
[{
"@type": "Evaluation",
"evaluates": "endpoint:plugins/sentiment140_0.2",
"evaluatesOn": "sts",
"metrics": [
{
"@type": "Accuracy",
"value": 0.872173058013766
},
{
"@type": "Precision_macro",
"value": 0.9035254323131467
},
{
"@type": "Recall_macro",
"value": 0.8021249029415483
},
{
"@type": "F1_macro",
"value": 0.8320673712021136
},
{
"@type": "F1_weighted",
"value": 0.8631351567604358
},
{
"@type": "F1_micro",
"value": 0.872173058013766
},
{
"@type": "F1_macro",
"value": 0.8320673712021136
}
]
}]
[ ]:

